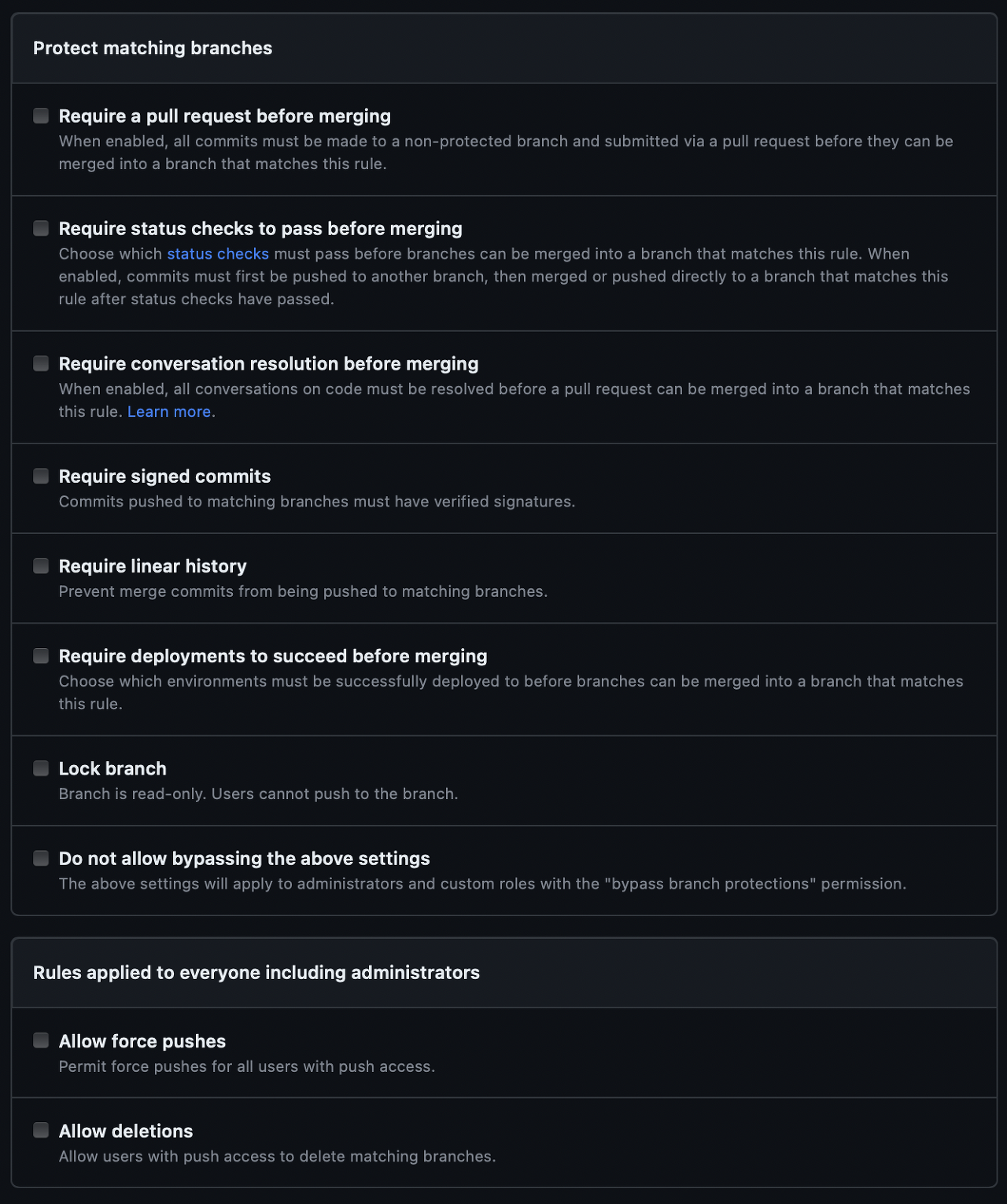
1. 컨테이너 기술이란? - 모놀리스 애플리케이션에서 MSA 으로 독립적 배포가 가능해지면서 발생한 관리 및 종속성 문제 해결 - 격리된 실행 환경 제공, 호스트 OS 에서 독립된 프로세스로 실행되어 자원 소비 및 오버헤드 최소화
2. 도커란? - 컨테이너 기술을 사용해서 애플리케이션을 패키징, 배포, 실행하기 위한 오픈 소스 플랫폼 - 도커 파일로 이미지를 빌드하고, 이미지로 컨테이너를 실행한다.
3. 도커 파일, 도커 이미지, 도커 컨테이너의 개념은 무엇이고, 서로 어떤 관계입니까? - 도커 파일(Dockerfile) - 도커에서 이미지를 생성하기 위해 작성하는 파일. - 컨테이너 설정을 정의한 것 - 도커 이미지(Docker Image) - 실행 가능한 컨테이너의 빌드된 상태 - 애플리케이션을 실행하기 위한 모든 환경을 포함한다. - 도커 컨테이너(Docker Container) - 도커 기반 컨테이너 이미지에서 생성된 리눅스 컨테이너 - 실행 중인 컨테이너는 도커를 실행하는 호스트에서 실행되는 프로세스 - 호스트와 호스트에서 실행 중인 다른 프로세스와 격리되어 있다.
name: 'Workflows name'
on: push // on은 script 가 언제 돌아가야하는지에 대한 부분 -> push 가 들어갈 때마다 실행된다.
jobs: // 스크립트가 해야하는 행동
first-job: // job의 이름이고, 정해진 규칙은 없다.
name: 'First Job' // name에 지정한 것은 각각 안에서 여러가지 나뉘는데 각각 job에 대한 이름 설정 안하면 위에 셋팅한 이름으로 default
runs-on: ubuntu-latest // 어느 가상 환경에 올릴 것인지 보통 3가지 - windows mac linux
steps:
- name: Say Hello World 1
shell: bash
run: |
echo "Hello World from step 1"
- name: Say Hello World 2
shell: pwsh
run: |
echo "Hello World from step 2"
클라이언트-서버 프로토콜 : 클라이언트 요청을 생성하기 위해 연결을 연 다음 응답을 받을 때 까지 기다리는 모델
데이터 스트림이 아닌, 개별적인 메시지 교환으로 통신
request(요청) : 클라이언트(브라우저)에 의해 전송되는 메시지
response(응답) : 서버에서 응답으로 전송되는 메시지
애플리케이션 계층 프로토콜
신뢰 가능한 전송 프로토콜을 사용한다.
주로 TCP TLS(암호화된 TCP) 사용
프록시(Proxy)
웹 브라우저와 서버 사이에 있는 많은 컴퓨터와 머신이 HTTP 메시지를 이어 받고 전달한다.
애플리케이션 계층에서 동작하는 컴퓨터/머신
프록시로 다양한 기능 수행 가능
캐싱
필터링
로드밸런싱
인증
로깅
HTTP 특징
간단한 사용
확장 가능 : HTTP 헤더를 통해 확장 가능
무상태(Stateless), 세션
HTTP 쿠키를 통해 상태가 있는 세션을 만든다.
헤더 확장성을 사용해서 동일한 컨텍스트 또는 동일한 상태를 공유하기 위해 각각의 요청들에 세션을 만들도록 HTTP 쿠키 추가
HTTP 통신 과정
1. TCP 연결을 연다. : 요청을 보내거나 응답을 받는 데 사용
2. HTTP 메시지 전송(request)
- HTTP2는 캡슐화되어 직접 읽기 불가능
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
3. 서버가 보낸 응답을 읽는다.
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
4. 연결을 닫거나 다른 요청을 위해 재사용
HTTP Message 구조
시작 줄(start-line) : HTTP 요청 / 요청에 대한 성공 또는 실패
HTTP 헤더 : 요청에 대한 설명 / 메시지 본문에 대한 설명
빈 줄 : 요청에 대한 모든 메타 정보가 전송되었음을 알린다. (헤드와 본문 사이)
본문(optional) : 요청과 관련된 데이터(HTML form) / 또는 응답과 관련된 문서가 선택적으로 들어간다.
HTTP Requset
클라이언트가 서버로 전달하는 메시지
request line : HTTP method + url + http version
header(헤더)
request header
client의 IP, 사용 언어(accept language), content type(파일 형식), referer(이전 페이지 주소)
general header : 메시지 전체에 적용, connection(네트워크 접속 유지할지 유무)